Figure 20. Rolling Back Units of Work
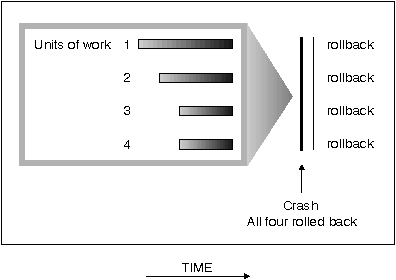 |
The database then needs to be moved to a consistent and usable state. This is done by rolling back incomplete transactions and completing committed transactions that were still in memory when the crash occurred.
You can do this by entering a RESTART DATABASE command. If you want this done in every case of a failure, then you should consider the use of the automatic restart enable (autorestart) configuration parameter. The default for this configuration parameter is that the RESTART DATABASE routine will be started every time it is needed. When (autorestart) is enabled, the next connect request to the database after the failure causes RESTART DATABASE to be executed.
Crash recovery always moves the database to a consistent and usable state. If crash recovery occurs for a database that is enabled for forward recovery (that is, the logretain or userexit configuration parameter is on for the database), and an error occurs during crash recovery that is attributable to an individual table space, that table space is taken off-line. Crash recovery continues. The table space taken off-line is placed in a roll-forward pending state.
At the completion of crash recovery, the other table spaces in the database are still usable and connections to the database can be established. (There are exceptions involving the table spaces that have the temporary tables or the system catalog tables. These will be discussed under roll-forward recovery.)
Following crash recovery, you may need to take additional action. You may need to work with the table spaces taken off-line as mentioned above. You may need to conduct a restore recovery and/or a roll-forward recovery depending on the error.
Figure 21. Restoring a Database
 |
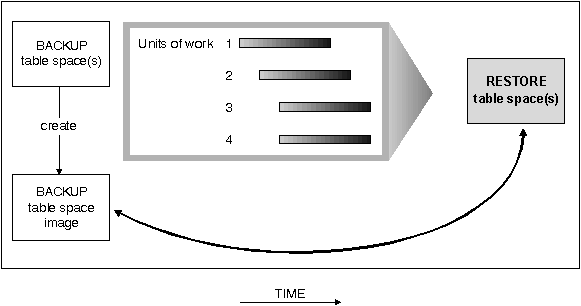
A database restore will rebuild the entire database using a backup of the database made at some point earlier. A backup of the database allows you to restore a database to a state identical to the time when the backup was made. Every unit of work from the time of the backup to the time of the failure is lost. (The need to re-create these units of work introduces the possibility of the next recovery method, roll-forward recovery, which is discussed later.)
Using the database restore recovery method, you must schedule and perform a full backup of the database on a regular basis.
In a partitioned database environment, the database is located across many database partition servers (or nodes). You must restore all database partitions, and the backups that you use for the RESTORE must all have been taken at the same time. (Each database partition is backed up and restored separately.) A backup of each database partition taken at the same time is known as a version backup.
Recoverable databases have either the logretain or userexit (or both) database configuration parameters turned "on". This allows for active and archived logs to be kept and results in the ability for the database to have roll-forward recovery. Table space BACKUP and RESTORE, and online BACKUP and RESTORE, are applicable to recoverable databases only.
Non-recoverable databases have both logretain and userexit turned "off". Only active logs are kept for crash recovery; no roll-forward recovery is allowed. Restore recovery using offline backups is the primary means of recovery for problems with this mode of database.
The scenarios that you need consider at this point are:
- Database roll-forward recovery, which follows the restore of
the database with the application of database logs. The database logs record
all changes made to the database. This method completes the recovery of the
database to a state identical to the time just before the failure.
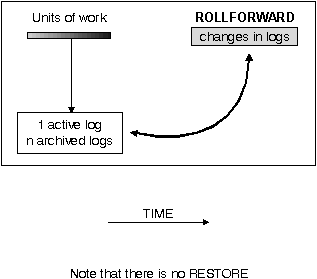
Figure 22. Database Roll-Forward Recovery
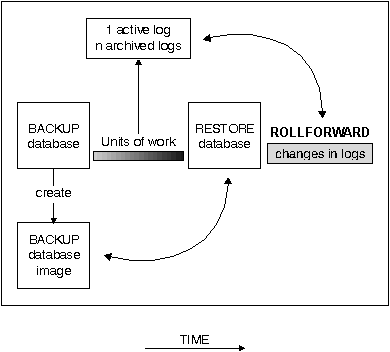
To use the database roll-forward recovery method, you must have created a backup of the database as well as archiving the logs by enabling either logretain or userexit. There are decisions that you must make regarding the logging procedure that you use. (Logging is discussed in more detail later. See the section on "Database Logs".)
In a partitioned database system, the database is located across many database server partitions. In this environment, if you are performing point-in-time roll-forward recovery, all database partitions must be rolled forward to ensure that all partitions are at the same level. If you need to restore a single database partition, you can perform roll-forward recovery to the end of the logs to bring it up to the same level as the other database partitions in the database.
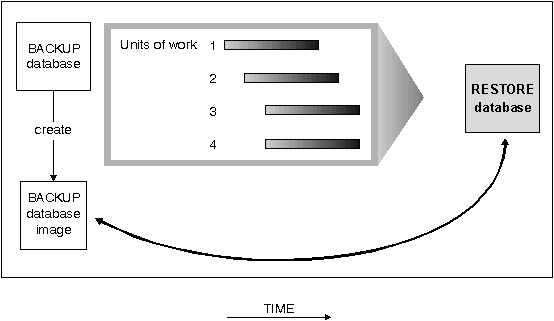
- When the database is enabled for forward recovery, it is also possible to
back up and restore table spaces. Table space restore requires a
backup made using BACKUP. This backup can be of the entire database (all of
the table spaces) or of one or more individual table spaces. This method
restores the selected table spaces to a state identical to the time the backup
was made.
Notes:
- Those table spaces not selected at the time of the BACKUP will not be in the same state as those that were restored.
- Using the table space restore recovery method, you must identify "key" table spaces in the database to be recovered as well as schedule and perform a backup of the database or the "key" table spaces on a regular basis.