
The following section describes concepts unique to IBM Replication.
A replication subscription defines the source-to-target relationship between the replication source and a target table. It also defines the structure of a target table and how the Apply program replicates data to the target table. A replication subscription can contain one or more of these definitions, called members. A replication subscription can be used to group one or more members for consistency. Changes are replicated from all replication source tables to the target tables by replicating the changed data for all the members in one subscription cycle; one unit of work at the target server.
Because the replication subscriptions have something in common, the changed data needs to be copied in the same unit of work. Each replication subscription has a name and is identified by a row in the subscription set control table. A replication subscription with replica tables has two rows, one for each direction of copying (from source to replica and replica to source).
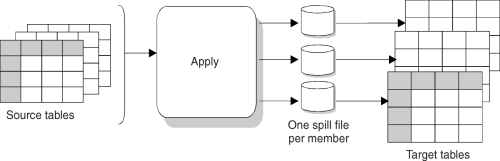
Figure 6 shows the relationship of the replication subscription with the Apply program.
Figure 6. Replication Subscriptions and the Apply Program
|
The Apply program reads changes from the replication source or CD table and creates one spill file created for each table. The Apply program replicates the changes to the target tables.
See "Data Consistency Requirements" for more information about replication subscription rules and recommended uses.
A before-image column is a copy of a column before it is updated. DB2 logs both the before-image and after-image columns of the table for each change to the table. A before-image copy is useful in some industries that require auditing or application rollback capability.
When you specify to capture before-image columns, the before- and after-image columns in the target table have the following values when the source column changes:
When the target table is initialized (or full refreshed due to a Capture program cold start), before-image columns have NULL values. Full refresh copies are from the source table, so no before-image values are available. For example, the before-image columns of a point-in-time target table have NULL values if the replication source table has no updates because no before-image columns were copied.
IBM Replication offers you many choices for target table structures. Depending on the kind of data you want in your application system, you can choose how changes are copied to the target table. Target tables function as historical or trend information, sources for update-anywhere replication, or simply an identical copy of the source table.
A user copy table reflects a valid state of the source table, except for subsetting and data enhancement, but not necessarily the most current state. Because the tables are physical objects, references to user copy target tables (or any other target table type) reduce the contention that results from too much direct access to the source tables. Accessing local user copy tables is much faster than using the network to access remote source tables for each query.
A point-in-time table contains an added system column, the approximate timestamp of when the particular row was inserted or updated at the source system. Otherwise, a point-in-time table is much like a view of the source table, but at some time in the past. Point-in-time copies reflect a valid state of the source table, but not necessarily the most current state.
Queries with column functions (AVG, MAX, MIN, SUM, COUNT) are very useful. They can range over many thousands of qualifying rows, yet they return very compact, easy-to-understand results.
By adding a timestamp and aggregating the results of these calculations, you can track broad trends, while still retaining the benefits of data reduction and compact storage.
Aggregate tables are built when rows are added or appended to the table over time.
Replica tables are very similar to user copy tables, except that replica tables are the only target type that an application can update and have its changes replicated back to the replication source table. A replica is a source of updates to the replication source and other replicas.
Some target table types are designed to become sources for additional replication. The CCD table and the replica table are almost always used in multiple tier or circular replication scenarios and are automatically defined as replication sources after they have been defined as part of a replication subscription.
After you define these tables as replication sources, they are immediately available as sources for additional replication subscriptions.
You can define run-time processing statements using SQL statements and stored procedures before and after the Apply program processes the replication subscription. This feature is useful for pruning CCD tables and controlling the sequence in which replication subscriptions are processed. The run-time processing statements can be run at the source server before the replication subscription is processed, and at both the source and target servers after the replication subscription is processed. The stored procedures use the SQL CALL statement, newly supported by IBM Replication, without parameters. The run-time procedures are executed together in a single unit-of-work. Acceptable SQLSTATEs can be defined for each processing statement as well.
Large amounts of data to be replicated often need to be broken down into more manageable sizes to prevent spill file or log overflows. For example, following an extensive Apply program outage, if a large block of change data has accumulated in the CD tables, breaking down the block of data prevents spill file overflows if you have limited disk space for the spill file.
You can use the blocking factor to specify how many minutes worth of change data can move in a subscription cycle. If the accumulation of change data is greater than the number of minutes specified, the Apply program converts a single subscription cycle into many mini-cycles, reducing the backlog to manageable pieces. This reduces the stress on the network and DBMS resources and reduces the risk of failure. If a failure occurs during one of the mini-cycles, then only the failed mini-cycle needs to be redone. When the Apply program later retries the replication subscription, it will resume from the point following the last successful mini cycle. Figure 7 shows how the changed data is broken down into subsets of changes.
Figure 7. Data Blocking Value. You can reduce the amount of data being replicated at a time by specifying a blocking value. 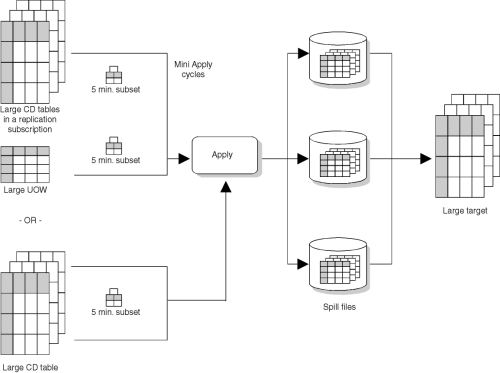
The column MAX_SYNC_MINUTES in the ASN.IBMSNAP_SUBS_SET control table contains the value you specify and uses it as a time-threshold limit that regulates the amount of changed data that the Apply program fetches and applies during a given subscription cycle. The Apply program uses this value to determine the interval upper bound on the amount of data to copy. When it reaches the upper bound, the Apply program ends the cycle.
The Apply program determines when to start a subscription cycle based on the information you provide while defining the replication subscription. You can set an interval or relative timing schedule, or trigger the Apply program with events to start processing a replication subscription.
Relative timing is copying on a specified interval. You determine a specific start time, date, and interval, which can be a set number of minutes or continuous copying. Relative time intervals are approximate. The Apply program will begin processing the replication subscription as soon as it can, based on its work load and the availability of resources.
Event timing is copying that is triggered by an event. You specify an event name that will trigger the Apply program and have an application populate the event table with a timestamp. When the Apply program reads the event control table and the time has lapsed, it begins processing the replication subscription.
The event control table, ASN.IBMSNAP_EVENT has three columns as shown in Table 2.
Table 2. The Event Control Table
| EVENT_NAME | EVENT_TIME | END_OF_PERIOD |
| END_OF_DAY | 1997-12-01-17:00:00.000000 | 1997-12-01-15:00:00.000000 |
EVENT_NAME is the event that you specify while defining the replication subscription. The Control Center populates this column after the replication subscription has been defined. EVENT_TIME is the timestamp for the time when the Apply program begins processing the replication subscription. END_OF_PERIOD is an optional value that indicates that transactions after this time should be deferred until a future date.
In Table 2, END_OF_DAY is the event name that the administrator specified while defining the replication subscription. The timestamp value, 1997-12-01-17:00:00.000000, is the time when the Apply program is to begin processing the replication subscription. The timestamp value, 1997-12-01-15:00:00.000000, is the transaction time when changes are no longer replicated; these transactions will be replicated on the next day's business cycle.
Your applications post events, not the Control Center. You tie your applications to subscription activity through named events. If you post an entry using CURRENT TIMESTAMP for EVENT_TIME, then you trigger the event named by EVENT_NAME. Any replication subscription tied to this event is now eligible to run. If you like, you can post events in advance, such as next week, next year, or every Saturday. As long as the Apply program is running, the Apply program will start at approximately the time that you specify. If the Apply program is stopped at the time you specify, and then restarted later, it checks the event table, notices the posted event, and begins processing the replication subscription.
One of the advantages of IBM Replication is that it allows you to stage changed data; that is, the Capture program captures changes to a source table only once and inserts change data rows into a CD table. The Apply program then pulls the changes from the CD tables. The Capture program also automatically prunes change data rows from change data (CD) tables when they are no longer needed; it does not, however, prune change data from consistent change data (CCD) tables.
A CD table receives an arbitrary number of change data rows from the Capture program that are not condensed. The CD table has no knowledge of transaction boundaries, or whether the transactions issuing the updates are committed, are incomplete, or are in flight. The Apply program joins the CD tables with the unit-of work (UOW) table to determine the committed changes to apply to copies. Uncommitted changes are eventually pruned, depending on the retention limit that you define in the Capture program tuning parameters control table.
Rows in a CD table reflect changes that are equivalent, if not identical, to the original operational updates. Uncommitted and incomplete changes can appear in rows in a CD table.
CCD staging tables are copies, defined in much the same way as point-in-time copies. They are the join of a the CD and UOW tables and contain only committed change data. Figure 8 shows which columns of the UOW table are included in the CCD table.
Figure 8. The CCD Table. This table is the join of the UOW table at the source server and the CD table for the replication source table. 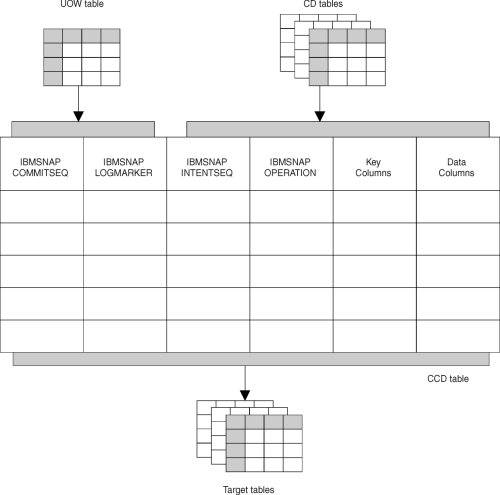
Table 3 shows the options that you have when you define these staging tables, and
which options are the default selected by the Control Center.
Table 3. CCD Staging Table Attributes
| CCD Is Local to: | Is CCD Complete? | Is CCD Condensed? | How Can CCD be Used in This Configuration? | ||||
|---|---|---|---|---|---|---|---|
| Source table | Y1 | Y | The CCD table is redundant with the local user table, and is therefore not usable as a history. | ||||
| Remote copies | Y2 | Y | As a remote staging table, where history retention is not required. | ||||
| Source table | N2 | Y | As a local staging table, which provides a stable source for synchronizing "fan out" copies. | ||||
| Remote copies | N1 | Y | By advanced users, who need to write their own apply programs to maintain indexed files or foreign DBMS tables. This configuration cannot support initialization of new point-in-time copies. | ||||
| Source table | Y1 | N | As local history table. | ||||
| Remote copies | Y2 | N | As remote history table. | ||||
| Source table | N2 | N | As a general-purpose, local staging table. When used with the original user table, this configuration can support copies that are complete histories. This table contains all change data for a given interval, but is not a complete history without the user table. | ||||
| Remote copies | N1 | N | By advanced users, whose application requirements are for change data only. This configuration cannot support initialization of point-in-time copies. | ||||
| |||||||
CCD staging tables hold captured changes from insert, update, or delete operations against a base table. CCD staging tables can be local to, or remote from, the original source.
A complete staging table contains every row of interest from the original source. A condensed staging table contains only the most current value for the row. Because condensed CCD tables do not have the same potential for unlimited growth as CD tables, they do not usually require pruning. Noncondensed CCD tables contain complete histories.
Apply inserts rows into noncondensed CCD tables; for condensed CCD tables, Apply updates rows already in the table. Apply uses CD and CCD tables as sources when maintaining replication subscriptions for point-in-time, change aggregate, and CCD target tables.
You can use staging tables to:
For example, you can use staging tables as part of a replication scenario that includes data from IMS and other sources. IBM's DataPropagator NonRelational can deliver IMS change data into a CCD staging table. You can then define the CCD table as a replication source.
With staging tables, you can set up sophisticated distribution networks and balance your work load across multiple DBMSs. You can copy DB2 for MVS changes to a DB2 Universal Database database, and then have, for example, 50 other replication subscriptions referring only to the staging table. In this way, the DB2 for MVS database is required to maintain only one set of copies directly, although dozens of copies are maintained indirectly.
When you create the first CCD table in a replication subscription of a source table and store the target table at the same source server, the target table is called an internal CCD table. Internal CCD tables are created by joining the unit-of-work and CD tables locally. They serve as a local cache for committed changed data.
If you create a second CCD table replication subscription against that source table, and store the target table at the same source server, the target table is called a local CCD table; only the first CCD at the source server is the internal CCD. Figure 9 shows an example of an internal or local CCD table that replicates changes to two target tables.
Figure 9. An Internal or Local CCD Table. The internal or local CCD table is located at the source server. 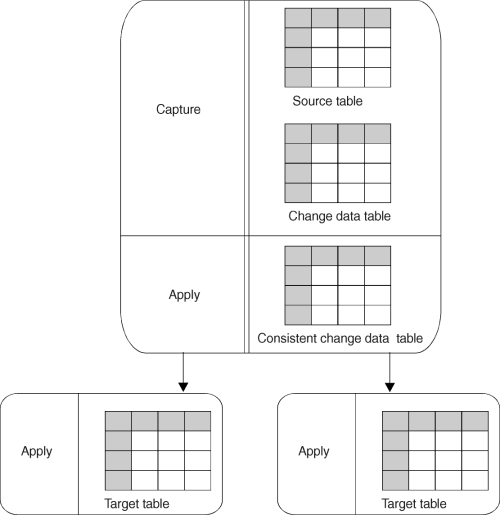
A CCD table at a server which is not the source server is called a remote CCD table. The remote CCD table can be located at the target server or an intermediate staging server as shown in Figure 10.
Figure 10. A Remote CCD Table. The remote CCD table is located at an intermediate staging server. 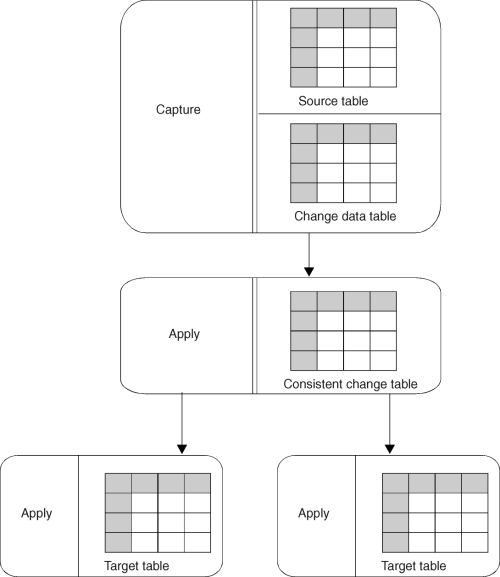
When you subscribe to a source table, the Control Center automatically defines certain target tables as a replication source for further copying, known as auto-registration. However, internal CCD tables are auto-registered differently than CCD tables. When internal CCD tables are auto-registered, replication source information is stored in the CCD_OWNER and CCD_TABLE columns of the source table row in the register control table. Staging tables created in subsequent replication subscriptions are defined as replication source tables.
This difference in auto-registration means that you cannot create replication subscriptions against internal CCD tables. Instead, you create replication subscriptions against the replication source table. The Apply program follows the hierarchy described in "How the Apply Program Selects a Source Table" to select a source table from which to copy. In most cases, the Apply program chooses the CCD table associated with the source table.
Changes captured within applications or other system tools, such as DataPropagator NonRelational, can also be defined as sources for replication subscription. The external data source must provide a complete CCD table and the CCD table must be updated by the application. For example, if an IMS segment is the source, DataPropagator NonRelational updates the DB2 CCD table. If the source table is not from IMS, you will need another program to update the CCD table. You can then define the CCD table as a surrogate replication source table with the Control Center. The CCD table can be stored and defined as a replication source in any supported database. You can then define replication subscriptions, regardless of whether the original transaction updates occurred in an IMS or DB2 database.
IBM Replication supports both transaction-based replication (replication of every update used by every transaction) and nontransaction-based replication (replication of just the net results of the recent activity).
The following example illustrates the difference between the two types:
Transaction 1: Update table1 set col1 = 'X' where key1 = 425
Update table2 set col2 = 'B' where key2 = 425
Transaction 2: Update table1 set col1 = 'Y' where key1 = 425
Transaction 3: Update table1 set col1 = 'Z' where key1 = 425
In transaction-based replication, all four transactions are captured and
replicated. In transaction-consistent replication, only the second update in
Transaction 1 and Transaction 3 are replicated.
Transaction-based replication is necessary in update-anywhere scenarios.
Transaction-consistent replication is superior to transaction-based replication because it produces the same change data results with fewer updates actually replicated. This type of replication reduces network load and can increase the availability of the target table.
You can implement transaction-consistent replication by using the internal CCD table model. In this model, outbound queues are condensed before replication, keeping only the latest captured value for each row. The Apply program condenses the queues by copying noncondensed change data already in the CD table into an internal (local) condensed CCD table. This CCD is then used as the source for replicating changes to the target table. Figure 9 shows the configuration of an internal or local CCD table.
When an Apply program refreshes an external CCD table, it deletes all of the rows from the pruning control table associated with the CCD table. The missing CCD table rows in the pruning control table indicate a full refresh and alert the Apply program that replication subscriptions based on the external CCD table must also be refreshed.
The Apply program keeps track of replication subscriptions based on the external CCD table in the following way:
You can define any number of replication subscriptions for CCD tables that refer to a source table. You can also define replication subscriptions referring to CCD tables that are remotely located from the original source table. In this sense, remote CCD tables become surrogate source tables. This introduces distribution databases or warehouses that serve as sources for all other copies. Changes captured on your operational systems need only be replicated once to the warehouse database to be applied to CCD tables in the warehouse database. These CCD staging tables can then serve as surrogate source tables for all other replication subscription definitions.
When the Apply program refreshes or updates a target, it chooses from a list of potential source tables in the following order:
In some cases, the source table considered first might not be the one that the Apply program reads from. For example, if the target table is a point-in-time table but has not yet been initialized, the Apply program must use a source table that is complete. If the CCD table is not complete (that is, CCD_COMPLETE=N in the register control table), the replication source table is selected as the refresh source. (The complete attributes are set when the CCD table is created.)
CCD tables and point-in-time (PIT) tables are changed, rather than appended. The originally captured operation code in the IBMSNAP_OPERATION column and the sequence numbers, IBMSNAP_INTENTSEQ and IBMSNAP_COMMITSEQ, are copied into and out of CCD staging tables. For condensed CCD tables, only the latest values are kept for any given row. The copy operation in IBMSNAP_OPERATION is an insert, update, or delete. The codes are:
Exceptions:
| Result: | The insert becomes an update. |
| Result: | The update becomes an insert. |
| Result: | The condition is ignored by Apply. |
The pull versus push configuration is a question of where the Apply program is running: at the source server or the target server. In the push method, the Apply program runs at the source server. In the pull method, the Apply program runs at the target server. The level of granularity is at the replication subscription level; one Apply program could be pushing for some replication subscriptions and pulling for others.
When the Apply program processes a replication subscription, it first connects to the source server to fetch the current changed data. This data is fetched into a spill file that is local to the Apply program. Once the data has been retrieved, the Apply program connects to the target server and applies the changes, one row at a time, as an INSERT, UPDATE, OR DELETE to each target table.
Figure 11 shows the difference between push and pull modes.
Figure 11. Push Versus Pull Mode
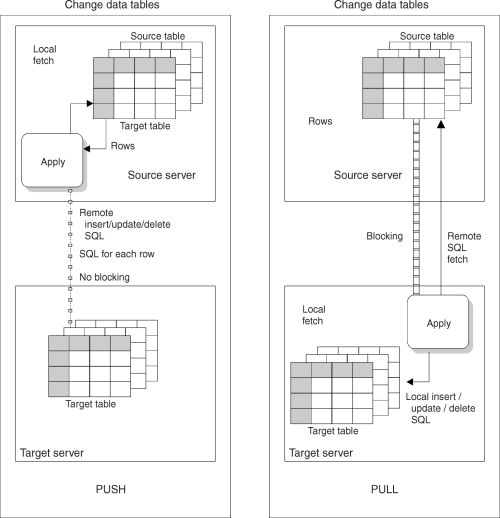 |
In pull mode, the Apply program connects to the remote source server to retrieve the data. DB2 can then use block fetch to pass the data across the network efficiently. When all data has been retrieved, the Apply program connects locally to the target server and applies the changes to the target table. The row-by-row process occurs as a local operation.
In push mode, the Apply program connects to the local source server and retrieves the data. Then it connects to the remote target server and pushes the updates to the target table. The row-by-row process occurs as a remote operation, with no blocking for network efficiency.
You do not have to do any special configuration to set up a push or pull configuration, except decide where to run the Apply program. The replication components and the Control Center recognize both configurations. The Control Center automatically sets up the replication control tables so the Apply program can push or pull data.
Generally, a pull configuration performs better than a push configuration because it allows more efficient use of the network. However, under the following circumstances a push configuration is a better choice:
Update-anywhere replication allows you to replicate changes from replication sources to target tables and from target tables back to the replication source table. With the Capture program running at both the source and target servers, changes against the original user table (the replication source object) and its updatable copy (replica) can both be captured, and the Apply program then replicates these changes from one server to the other to maintain data currency. This is also true for a one-to-many configuration (one source table to many replicas); changes to the replication source table can be copied to all of its replicas, and changes to any of the replicas can be copied to the replication source table. The changes are then copied to all other replicas.
Figure 12 shows a basic update-anywhere replication model. Changes are originated at both the source and replica tables.
Figure 12. Update-Anywhere Replication. Update-anywhere replication is used to replicate changes from both the source and target servers. 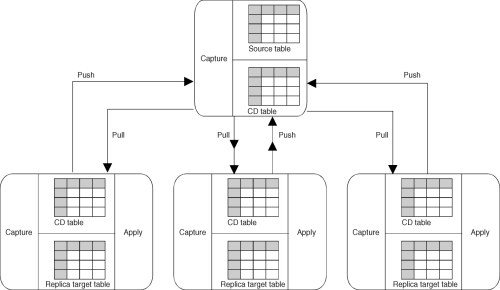
The Apply program detects update conflicts, after they occur, during the subscription cycle. When transactions are rejected, the Apply program compensates the transactions at the replica. During this process, the Apply program inserts rejection codes for every rejected transaction in the IBMSNAP_REJ_CODE column of the UOW control table. Conflict detection is provided at three levels: no detection, standard detection, and enhanced detection, specified while defining the replication source. When a conflict is detected and compensated, the replication subscription fails. All related transactions are checked for conflicts and are rejected also.
Conflict detection cannot detect read-transaction conflicts. If, for example, an application reads information that is subsequently removed by compensation, the dependency cannot be detected.
After the Apply program completes the subscription cycle, the ASNDONE exit notifies you that the cycle is complete and whether there were conflicts. You can use the ASNDONE user exit to manage recovery from conflicts.
See "Update-Anywhere Replication" for more detailed information about these concepts and suggestions for implementing update-anywhere replication. See the Capture and Apply program chapter for your platform in this book for more information about ASNDONE.
You can define source views or target subset views.
Using the Control Center, you can define a join as a replication source. The joins can only include tables defined as replication sources. If the replication sources defined in the join have CD (or CCD) tables, a CD view is created from the replication sources' CD tables. The Capture program (or the Apply program, for CCD sources) maintains the control information for the joined replication sources and the CD views in the source server control tables.
Join views fill many requirements, both for denormalizing (restructuring) copies in data warehouse scenarios, enabling easier querying of copied data, and also for addressing the routing problem, sometimes called the database partitioning problem in distributed computing scenarios. For example, knowing where to send a bank account update may require a join of the account table with the customer table, in order to know which branch of the bank the customer deals with. Typically, production databases are normalized so that the geographic details, such as branch-number, are not stored redundantly throughout the production database.
IBM Replication supports the following types of view definitions:
You use the target views only when consolidating data from multiple sources, such as multisite union scenarios. Multiple source tables are updated and consolidated into a join at the target server. These types of views are not supported in the Control Center.
When the target table is maintained by different servers or different replication subscriptions, a subset view ensures that the DELETE statement generated before a full-refresh is copied to the appropriate horizontal fragment. The Apply program is almost always driven by SQL operations at the source server and in addition, generates an unqualified DELETE statement at the target server before applying a full-refresh answer set. By defining a subset view over the target table, and defining the replication subscription target to be the view, you restrict the DELETE statement to the appropriate horizontal fragment. That way, a full refresh of data from the source does not affect the information from the other sources.
The mobile replication enabler allows you to operate the Capture and Apply programs in mobile mode for the occasionally connected environment. For applications that support a mobile work force or one in which clients infrequently connect, the mobile mode allows you to replicate on demand, whenever the source or target server is online.
With the mobile replication enabler you can request immediate capture of changed data and that the Apply program replicate data immediately to reduce network costs. See Chapter 16. "Mobile Replication" for planning, administration, and operating information.
The Capture program prunes the CD and UOW tables based on information inserted into the pruning control table by the Apply program. The Apply program maintains the log sequence number in the SYNCHPOINT column of the pruning control table. Initially, the Apply program sets this sequence number to zero when it performs a full refresh. A zero value signals the Capture program to start capturing. When the Apply program copies changes from the CD table to the target table, it updates the SYNCHPOINT column. The Capture program can then prune changes in the CD table up through the row with the highest log sequence number.
Pruning occurs depending on whether you start the Capture program with the PRUNE or NOPRUNE invocation parameter and how the prune interval is set in the tuning parameters table. See the Capture and Apply chapter for your platform in this book to learn how to set pruning.
The Capture program does not insert data into CCD tables and does not prune them. Instead, your application requirements should determine the history retention period for CCD tables (described in "Staging Changed Data"). Therefore, pruning of CCD tables is not automatic by default, but can be easily automated using an SQL statement to be processed after the subscription cycle.
Occasionally, a gap can occur between the capturing of the changed data for a source table and the replication of the changed data to the target table. When this happens, a user with sufficient privileges might need to reset the control table information before executing the definition again. However, to preserve data integrity, check the control tables and take any necessary action.
For example, if you shut down the Capture program and then cold start it, it deletes all rows from the CD table. (See the Capture and Apply chapter for your platform in this book to learn more about cold start.) Between the time you shut down the Capture program and cold started it, updates might have been made that the Capture program did not capture. Additionally, any updates that were in the CD table were deleted at the cold start before the Apply program could copy them. A gap now exists between the target table and the CD table.
When a gap is present, the Apply program attempts to refresh complete copies unless the target table is not complete (COMPLETE=N). If the target table is not complete and the Apply program cannot perform a refresh, data integrity could be lost. In this case, before you reset the copy definition and resume copying, you need to check:
The Capture and Apply programs use the synchpoint to coordinate their work. The synchpoint is the log sequence number and indicates the progress of the replication subscription through a subscription cycle. The Capture and Apply programs maintain and use this value to prevent the pruning of data that the Apply program did not copy. The synchpoint value is maintained in the SYNCHPOINT column of the subscription set control table.
To verify whether a gap exists:
Compare the SYNCHPOINT column in the subscription set control table with the CD_OLD_SYNCHPOINT column in the register control table. If SYNCHPOINT is lower than CD_OLD_SYNCHPOINT, a gap exists.
Determine whether continued performance or data integrity is more important.