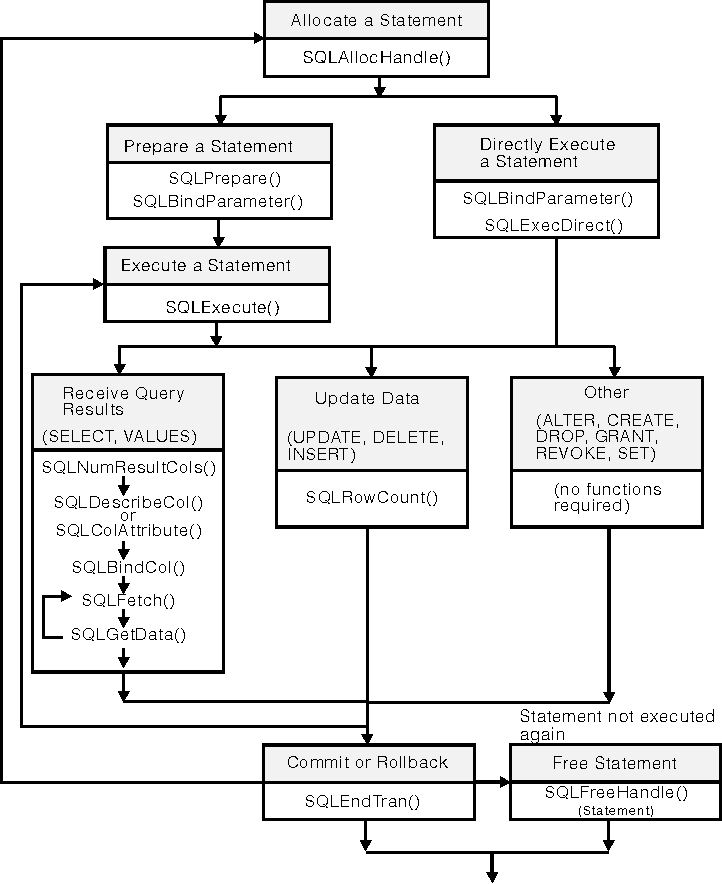

The following figure shows the typical order of function calls in a DB2 CLI application. Not all functions or possible paths are shown.
Figure 3. Transaction Processing
|
Figure 3 shows the steps and the DB2 CLI functions in the transaction processing task. This task contains five steps:
SQLAllocHandle() is called with a HandleType of SQL_HANDLE_STMT to allocate a statement handle. A statement handle refers to the data object that is used to track the execution of a single SQL statement. This includes information such as statement attributes, SQL statement text, dynamic parameters, cursor information, bindings for dynamic arguments and columns, result values and status information (these are discussed later). Each statement handle is associated with a connection handle.
A statement handle must be allocated before a statement can be executed.
The maximum number of statement handles that may be allocated at any one
time is limited by overall system resources (usually stack size). The maximum
number of statement handles that may actually be used, however, is defined by
DB2 CLI (as listed in Table 1). An HY014 SQLSTATE will be returned on the call to SQLPrepare()
or SQLExecDirect() if the application exceeds these limits.
Table 1. Maximum Number of Statement Handles Allocated at one Time
| Isolation Level | Without Hold | With Hold | Total |
|---|---|---|---|
| Cursor stability | 296 | 100 | 396 |
| No commit | 296 | 100 | 396 |
| Repeatable read | 196 | 200 | 396 |
| Read stability | 296 | 100 | 396 |
| Uncommitted read | 296 | 100 | 396 |
Once a statement handle has been allocated, there are two methods of specifying and executing SQL statements:
The first method splits the preparation of the statement from the execution. This method is used when:
The second method combines the prepare step and the execute step into one. This method is used when:
| Note: | SQLGetTypeInfo() and the schema (catalog) functions discussed in Chapter 3. "Using Advanced Features", execute their own query statements, and generate a result set. Calling a schema function is equivalent to executing a query statement, the result set is then processed as if a query statement had been executed. |
DB2 Universal Database version 5 or later has a global dynamic statement cache stored on the server. This cache is used to store the most popular access plans for prepared SQL statements. Before each statement is prepared, the server searches this cache to see if an access plan has already been created for this exact SQL statement (by this application or any other application or client). If so, the server does not need to generate a new access plan, but will use the one in the cache instead. There is now no need for the application to cache connections at the client unless connecting to a server that does not have a global dynamic statement cache (such as DB2 Common Server v2). For information on caching connections at the client see "Caching Statement Handles on the Client" in the Migration section.
Both of the execution methods described above allow the use of parameter markers in place of an expression (or host variable in embedded SQL) in an SQL statement.
Parameter markers are represented by the '?' character and indicate the position in the SQL statement where the contents of application variables are to be substituted when the statement is executed. The parameter markers are referenced sequentially, from left to right, starting at 1. SQLNumParams() can be used to determine the number of parameters in a statement.
When an application variable is associated with a parameter marker it is bound to the parameter marker. The application must bind an application variable to each parameter marker in the SQL statement before it executes that statement. Binding is carried out by calling the SQLBindParameter() function with a number of arguments to indicate, the numerical position of the parameter, the SQL type of the parameter, the data type of the variable, a pointer to the application variable, and length of the variable.
The bound application variable and its associated length are called deferred input arguments since only the pointers are passed when the parameter is bound; no data is read from the variable until the statement is executed. Deferred arguments allow the application to modify the contents of the bound parameter variables, and repeat the execution of the statement with the new values.
Information for each parameter remains in effect until overridden, or until the application unbinds the parameter or drops the statement handle. If the application executes the SQL statement repeatedly without changing the parameter binding, then DB2 CLI uses the same pointers to locate the data on each execution. The application can also change the parameter binding to a different set of deferred variables. The application must not de-allocate or discard variables used for deferred input fields between the time it binds the fields to parameter markers and the time DB2 CLI accesses them at execution time.
It is possible to bind the parameters to a variable of a different type from that required by the SQL statement. The application must indicate the C data type of the source, and the SQL type of the parameter marker, and DB2 CLI will convert the contents of the variable to match the SQL data type specified. For example, the SQL statement may require an integer value, but your application has a string representation of an integer. The string can be bound to the parameter, and DB2 CLI will convert the string to the corresponding integer value when you execute the statement.
By default, DB2 CLI does not verify the type of the parameter marker. If the application indicates an incorrect type for the parameter marker, it could cause either an extra conversion by the DBMS, or an error. Refer to "Data Types and Data Conversion" for more information about data conversion.
Information about the parameter markers can be accessed using descriptors. If you enable automatic population of the implementation parameter descriptor (IPD) then information about the parameter markers will be collected. The statement attribute SQL_ATTR_ENABLE_AUTO_IPD must be set to SQL_TRUE for this to work. See "Using Descriptors" for more information.
If the parameter marker is part of a predicate on a query and is associated with a User Defined Type, then the parameter marker must be cast to the built-in type in the predicate portion of the statement; otherwise, an error will occur. For an example, refer to "User Defined Types in Predicates".
The global dynamic statement cache was introduced in an earlier section. The access plan will only be shared between statements if they are exactly the same. For SQL statements with parameter markers, the specific values that are bound to the parameters do not have to be the same, only the SQL statement itself.
For information on more advanced methods for binding application storage to parameter markers, refer to:
The next step after the statement has been executed depends on the type of SQL statement.
If the statement is a query statement, the following steps are generally needed in order to retrieve each row of the result set:
If the application does not bind any columns, as in the case when it needs to retrieve columns of long data in pieces, it can use SQLGetData(). Both the SQLBindCol() and SQLGetData() techniques can be combined if some columns are bound and some are unbound. The application must not de-allocate or discard variables used for deferred output fields between the time it binds them to columns of the result set and the time DB2 CLI writes the data to these fields.
If data conversion was indicated by the data types specified on the call to SQLBindCol(), the conversion will occur when SQLFetch() is called. Refer to "Data Types and Data Conversion" for an explanation.
Data conversion can also be indicated here, as in SQLBindCol(), by specifying the desired target C data type of the application variable. Refer to "Data Types and Data Conversion" for more information.
To unbind a particular column of the result set, use SQLBindCol() with a null pointer for the application variable argument (TargetValuePtr). To unbind all of the columns with one function call, use SQLFreeStmt() with an Option of SQL_UNBIND.
Applications will generally perform better if columns are bound instead of using SQLGetData(). However, an application may be constrained in the amount of long data that it can retrieve and handle at one time. If this is a concern, then SQLGetData() may be the better choice. See "Using Large Objects" for additional techniques to handle long data.
For information on more advanced methods for binding application storage to result set columns, refer to:
If the statement is modifying data (UPDATE, DELETE or INSERT), no action is required, other than the normal check for diagnostic messages. In this case, SQLRowCount() can be used to obtain the number of rows affected by the SQL statement.
If the SQL statement is a Positioned UPDATE or DELETE, it will be necessary to use a cursor. A cursor is a moveable pointer to a row in the result table of an active query statement. (This query statement must contain the FOR UPDATE OF clause to ensure that the query is not opened as readonly.) In embedded SQL, cursors names are used to retrieve, update or delete rows. In DB2 CLI, a cursor name is needed only for Positioned UPDATE or DELETE SQL statements as they reference the cursor by name. Furthermore, a cursor name is automatically generated when SQLAllocHandle() is called with a HandleType of SQL_HANDLE_STMT.
To update a row that has been fetched, the application uses two statement handles, one for the fetch and one for the update. The application calls SQLGetCursorName() to obtain the cursor name. The application generates the text of a Positioned UPDATE or DELETE, including this cursor name, and executes that SQL statement using a second statement handle. The application cannot reuse the fetch statement handle to execute a Positioned UPDATE or DELETE as it is still in use. You can also define your own cursor name using SQLSetCursorName(), but it is best to use the generated name, since all error messages will reference the generated name, and not the one defined by SQLSetCursorName().
If the statement neither queries nor modifies the data, then there is no further action other than the normal check for diagnostic messages.
A transaction is a recoverable unit of work, or a group of SQL statements that can be treated as one atomic operation. This means that all the operations within the group are guaranteed to be completed (committed) or undone (rolled back), as if they were a single operation. A transaction can also be referred to as a Unit of Work or a Logical Unit of Work. When the transaction spans multiple connections, it is referred to as a Distributed Unit of Work.
DB2 CLI supports two commit modes:
The default commit mode is auto-commit (except when participating in a coordinated transaction, see "Distributed Unit of Work (Coordinated Distributed Transactions)"). An application can switch between manual-commit and auto-commit modes by calling SQLSetConnectAttr(). Typically, a query-only application may wish to stay in auto-commit mode. Applications that need to perform updates to the database should turn off auto-commit as soon as the database connection has been established.
When multiple connections exist to the same or different databases, each connection has its own transaction. Special care must be taken to call SQLEndTran() with the correct connection handle to ensure that only the intended connection and related transaction is affected. It is also possible to rollback or commit all the connections by specifying a valid environment handle, and a NULL connection handle on the SQLEndTran() call. Unlike distributed unit of work connections (described in "Distributed Unit of Work (Coordinated Distributed Transactions)"), there is no coordination between the transactions on each connection.
If the application is in auto-commit mode, it never needs to call SQLEndTran(), a commit is issued implicitly at the end of each statement execution.
In manual-commit mode, SQLEndTran() must be called before calling SQLDisconnect(). If Distributed Unit of Work is involved, additional rules may apply, refer to "Distributed Unit of Work (Coordinated Distributed Transactions)" for details.
It is recommended that an application that performs updates should not wait until the disconnect before committing or rolling back the transaction. The other extreme is to operate in auto-commit mode, which is also not recommended as this adds extra processing. Refer to the "Environment, Connection, and Statement Attributes" and SQLSetConnectAttr - Set Connection Attributes for information about switching between auto-commit and manual-commit.
Consider the following when deciding where in the application to end a transaction:
When a transaction ends:
For more information and an example refer to SQLEndTran - End Transactions of a Connection.
Call SQLFreeStmt() to end processing for a particular statement handle. This function can be used to do one or more of the following:
The SQL_DESC_COUNT field of the application row descriptor (ARD) will also be set to zero in this case. See "Using Descriptors" for more information on using descriptors.
The SQL_DESC_COUNT field of the application parameter descriptor (APD) will also be set to zero in this case. See "Using Descriptors" for more information on using descriptors.
Call SQLFreeHandle() with a HandleType of SQL_HANDLE_STMT to:
The columns and parameters should always be unbound before using the handle to process a statement with a different number or type of parameters or a different result set; otherwise application programming errors may occur.